
Memory Networks
Have you guys seen the movie Momento by Christopher Nolan…No worries! Let me explain you the idea. The protagonist in the film suffers from a syndrome referred to as short-term memory loss. He cannot make new memories!
Can we say that Neural networks if used as is, suffer from a similar syndrome? They can generalize, find patterns in the present example that they process, but can’t remember stuff. Although rote learning (overfitting and training without bias) is possible, however using memory and then combining it with the relevant information that we have in present to infer something conclusive…seems like a task for a neural network. Isn’t it? But we humans can do it. There should be some way of implementing this in neural networks as well.
Although with the advent of RNNs (Recurrent Neural Networks) and LSTMs (Long Short-Term Memory) sequential learning has been made possible. However, their memories are small and is not compartmentalized enough to accurately remember facts from the past.
For instance, if we want a learning model that can be used for solving a Reading Comprehension (RC), we need to collect facts from the complete RC and then based on the question, search for relevant information in it.
Here come memory networks. In October 2014 Facebook AI Research (FAIR) came up with an intriguing learning model referred to as memory network which could overcome this difficulty. These models maintain the individuality of every input by storing them in a potentially large memory component that can be read and written into. The model then can be trained using successful machine learning or deep learning strategies to learn how to operate efficiently with memory component and perform inference with it.
As the authors state in their paper:
“The central idea is to combine the successful learning strategies developed in the machine learning literature for inference with a memory component that can be read and written to. The model is then trained to learn how to operate effectively with the memory component.”
How would such a model look? Before delving into all sorts of complicated mathematics, let’s first try to decipher how we tackle such problems. Imagine yourself reading a maths problem from your high school textbook something like:
Alfred buys an old scooter for Rs. 4700 and spends Rs. 800 on its repairs. If he sells the scooter for Rs. 5800, his gain percent is?
You start reading the question and possibly write it as:
- Initial CP for the scooter: Rs 4700
The first feature fed into your memory. Then you read the next five words.
- Money spent on repairs: Rs 800
You feed in this vector and update your memory. You generalize these two sets of information as:
- Essentially this means that effective CP is : Rs 4700 + Rs 800 = Rs 5500. Isn’t it?
Again the next set of words suggest that he sold the scooter for some amount, so you convert this into a feature vector like:
SP of the scooter: Rs. 5800
This information again goes into your memory, and you update it.
Now the question asks his gain percent. So you calculate the profit using the current state of the memory:
- Profit = Effective SP - Effective CP
=> Profit = Rs. 5800 - Rs. 5500 = Rs. 300
The profit calculated is your output, but your response has to be the percentage. So you convert it into the desired response. That calculates the percentage:
%age profit = (Rs. 300/ Rs.5500) x 100 = 5.4%
That’s what comes out of your response module :p
With this example, we vaguely understand how a such a learning model could be designed.
However, how do we define this as an algorithm? Let’s delve into the specifics of the Memory Networks.
Let’s begin with an introduction to the basic architecture of a memory network.
A memory network consists of a memory M an array of object Mi (e.g. array of vectors) indexed by ‘i’ and four components:
- Input: You cannot feed in raw data, you need to convert it into a mathematical form. This component converts it into the internal feature representation. the way you were writing the statements for your understanding.
- Generalization: As you show the network more information, it needs to update old memories. Got the scooter, repaired it…sold it…We need to remember the sequence and update the information that we gather at each time step.
- Output: It will produce an output based on whatever is the memory state and what is being asked. The net profit is Rs.300 :P
- Response: It will produce exact desired response whatever is needed. The profit percentage!
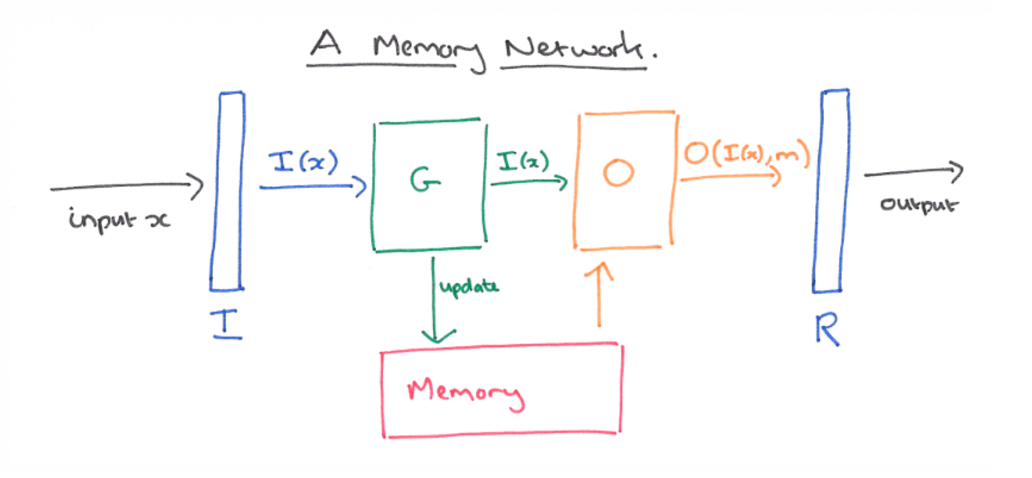
As this excellent post explains:
“The most basic version of their MemNN works as follows. I is given a sentence at a time, and G simply stores the sentence in the next available memory slot (i.e., we assume there are more memory slots than sentences). All of the hard work is done in the O and R components. O is used to find up to k supporting memories. The first memory is found by scoring the match between the input sentence and each sentence in memory, and returning the one with the highest score. For k > 1, the n_th memory (1 < n ≤ k) is found by comparing both the original input sentence and all of the n-1 supporting memories found so far against the sentences in memory. The sentence with the highest matching score is returned. The output of O is a list of sentences containing the original input sentence and the _k supporting sentences it has found . The simplest version of Rcan simply return the first supporting sentence, a more sophisticated version might use an RNN to perform sentence generation. A compromise is to limit textual responses to be a single word using a scoring function over all of the words in the dictionary and the sentences produced by O.”
In essence we understood the basic working model and idea behind the implementation of a memory network. In our next post we would be looking at how Deep Learning as a technique can be used to train a memory network from scratch.
Written By,
Harsh Agarwal and Deeksha Kaurav